概率论与数理统计
随机变量的分布
分布函数
F(x)=P{X≤k}
可推知
P{x1<X≤x2}=F(x2)−F(x1)
二元情况下有
F(x,y)=P{X≤x,Y≤y}
P{x1<X≤x2,y1<Y≤y2}=F(x2,y2)−F(x1,y2)−F(x2,y1)+F(x1,y1)
密度函数
F(x)=∫−∞xf(t)dt
称f(x)为X的概率密度函数
f(x)=F′(x)
二元情况下有
F(x,y)=∫−∞x∫−∞yf(u,v)dudv
P{(X,Y)∈D}=D∬f(x,y)dxdy
∂x∂y∂2F(x,y)=f(x,y)
边际密度函数
fX(x)=∫−∞+∞f(x,y)dyfY(y)=∫−∞+∞f(x,y)dx
条件密度函数
给定{X=x}的情况下Y的条件密度函数
fY∣X(y∣x)=fX(x)f(x,y)
P(X≤x∣Y=y)=∫−∞xfX∣Y(x∣y)dx
反函数的密度函数
Y=g(X),若函数g是一处处可导的严格单调函数,其值域为D,记y=g(x)的反函数为x=h(y),则Y的密度函数为
fY(y)={fX(h(y))⋅∣h′(y)∣,y∈D0,y∈/D
联合分布律
P{X=xi,Y=yj}=pij,i,j=1,2,...
边际分布律
P{X=xi}=j=1∑+∞pij=piP{Y=yj}=i=1∑+∞pij=pj
条件分布律
P{X=xi∣Y=yj}=P{Y=yj}P{X=xi,Y=yj},i=1,2,...
即给定给定Y=yj条件下的条件分布律
独立性
- X,Y相互独立当且仅当对任意实数x,y有
F(x,y)=FX(x)FY(y)
- X,Y相互独立当且仅当对任意实数xi,xj都有
P{X=xi,Y=yj}=P{X=xi}P{X=xj}
- X,Y相互独立当且仅当下式几乎处处成立(即面积等于0的区域可以不成立,具体参见课本。)
f(x,y)=fX(x)fY(y)
独立充要条件的定理
二维连续型随机变量X,Y相互独立的充要条件是X,Y的联合密度函数f(x,y)几乎处处可以写成x的函数m(x)和y的函数n(y)的乘积,即
f(x,y)=m(x)⋅n(y),−∞<x,y<+∞,
Z=X+Y的分布
二维离散型随机变量
显然有
P{Z=zk}=P{X+Y=zk}=i=1∑+∞P{X=xi,Y=zk−xi},k=1,2,...
同理
P{Z=zk}=P{X+Y=zk}=i=1∑+∞P{X=zk−yi,Y=yi},k=1,2,...
当X,Y相互独立时有
P{Z=zk}=P{X=xi}P{Y=zk−yi}
P{Z=zk}=P{X=zk−yi}P{Y=yi}
二维连续型随机变量
fz(z)=∫−∞+∞f(x,z−x)dy
fz(z)=∫−∞+∞f(z−y,y)dy
当X,Y相互独立时有
fZ(z)=∫−∞+∞fX(x)fY(z−x)dx
fZ(z)=∫−∞+∞fX(z−y)fY(y)dy
例题
设某服务台顾客等待时间(以min计)X服从参数为λ的指数分布,接受服务的时间Y服从区间(0.20)上的均匀分布,且设X,Y相互独立。记Z=X+Y.
(1)求Z的密度函数fZ(t)
(2)设λ=201,求等待与接收服务的总时间不超过45min的概率。
(1)由题意知
fX(x)={λe−λx,x>00,x≤0,fY(y)=⎩⎨⎧201,0<y<200,其他
由X,Y相互独立,可知X,Y的联合密度函数为
f(x,y)=fX(x)fY(y)=⎩⎨⎧201λe−λx,x>0,0<y<200,其他
即
f(x,t−x)=⎩⎨⎧201λe−λx,x>0,0<t−x<200,其他
fZ(t)=∫−∞+∞f(x,t−x)dx
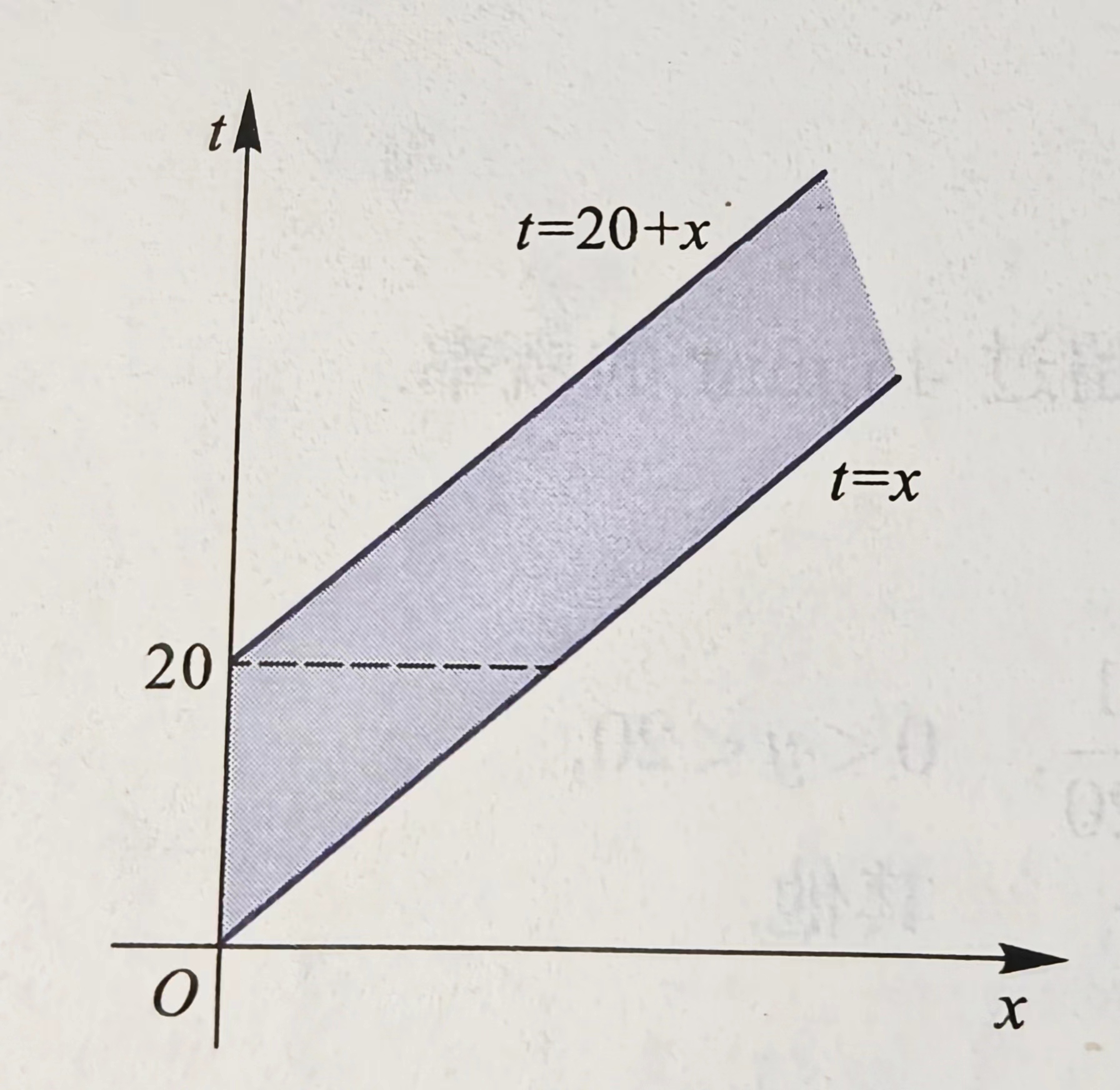
![]() 如图
如图
当t≤0时,fZ(t)=0
当0<t<20时,fZ(t)=∫0t201λe−λx=201(1−e−λt)
当t≥20时,fZ(t)=∫t−20t201λe−λx=201e−λt(e20λ−1)
(2)P{X≤45}=∫−∞45fZ(t)=0.8189
M=max{X,Y},m=min{X,Y}的分布
FM(t)=P{max{X,Y}≤t}=P{X≤t,Y≤t}=F(t,t)
当X,Y独立时
FM(t)=FX(t)⋅FY(t)
FN(t)=P{min{X,Y}≤t}=P{(X≤t)∪(Y≤t)}=FX(t)+FY(t)−F(t,t)
或者
FN(t)=1−P{X>t,Y>t}
当X,Y独立时
FN(t)=FX(t)+FY(t)−FX(t)FY(t)
推广到n元
FM(t)=i=1∏nFi(t)
FN(t)=1−i=1∏n[1−Fi(t)]
随机变量的数字特征
期望
对于离散型随机变量X
P{X=xi}=pi,i=1,2,3
若级数xipi绝对收敛,则称级数xipi为X的期望
对于连续型随机变量X,若
∫−∞+∞∣x∣f(x)<+∞
则称∫−∞+∞xf(x)<+∞为X的期望
E(g(X))=i=1∑ng(xi)pi
E(g(X))=∫−∞+∞g(x)f(x)dx
其中f(x)是X的密度函数
E(h(X,Y))=∫−∞+∞∫−∞+∞h(x,y)f(x,y)dxdy
其中f(x,y)是X,Y的联合密度函数
期望的性质
E(c0+i=1∑nciXi)=c0+i=1∑nciE(Xi)
- 若Xi(i=1,2,...,n)相互独立,且数学期望都存在,则有
E(i=1∏nXi)=i=1∏nE(Xi)
条件期望
给定X=x
E{Y∣x}=E{Y∣X=x}=j=1∑+∞yjpj(x)
E{Y∣x}=E{Y∣X=x}=∫−∞+∞yfY∣X(y∣x)dy
全期望公式
E(Y)=E[E(Y∣X)]
当(X,Y)为二维离散型随机变量时
E(Y)=i=1∑+∞E(Y∣X=i)P{X=i}
当(X,Y)为二维连续型随机变量时
E(Y)=∫−∞+∞E(Y∣X=x)fX(x)dx
方差
Var(X)=E[(X−E(X))2]
对于离散变量
Var(X)=i=0∑+∞(xi−E(X))2pi
对于连续变量
Var(X)=∫−∞+∞(x−E(X))2f(x)dx
Var(X)=E(X2)−E(X)2
推论:若某一随机变量平方的数学期望存在,则一定保证了这个随机变量数学期望的存在性。
方差的性质
- Var(cX)=c2Var(X)
- Var(X+c)=Var(X)
- 推广:Var(c0+i=1∑nciXi)=i=1∑nci2Var(Xi)
- Var(X)≤E[(X−c)2],当且仅当E(X)=c时等号成立
- 若X1,X2,...,Xn为两两独立的随机变量,方差都存在,则
Var(i=1∑nXi)=i=1∑nVar(Xi)
- X的方差存在时,Var(x)=0当且仅当P{X=c}=1,其中c=E(X)
协方差
Cov(X,Y)=E[(X−E(X))(Y−E(Y))]
对二维离散型变量
Cov(X,Y)=i=1∑+∞j=1∑+∞(xi−E(X))(yj−E(Y))pij
对二维连续型变量
Cov(x,y)=∫−∞+∞∫−∞+∞(x−E(X))(y−E(Y))f(x,y)dxdy
通常使用以下公式
Cov(X,Y)=E(XY)−E(X)E(Y)
协方差的性质
Var(i=1∑nXi)=i=1∑nVar(Xi)+21≤i<j≤n∑Cov(Xi,Xj)
- Cov(X,Y)=Cov(Y,X)
- Cov(X,X)=Var(X)
- Cov(aX,bY)=abCov(X,Y)
- Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y)
- 当Var(X)⋅Var(Y)=0时,有(Cov(X,Y))2≤Var(X)Var(Y),其中等号成立当且仅当X,Y有严格的线性关系
独立与相关
相关系数
ρXY=Var(X)Var(Y)Cov(X,Y)
若ρXY=0则称X,Y不相关
- ∣ρ(X,Y)∣≤1,其中等号成立当且仅当$X与Y之间有严格的线性关系。越接近1$X,Y$线性关系就越强
- ∣ρ(X,Y)∣>0时X,Y正相关;∣ρ(X,Y)∣<0时X,Y负相关;
不相关
- ρ(X,Y)=0
- Cov(X,Y)=0
- E(XY)=E(X)E(Y)
- Var(X+Y)=Var(X)+Var(Y)
- 独立一定不相关,但反之不然。
重要随机变量的概率分布
0-1(p)分布,两点分布
- 符号: X∼0−1(p)
- 概率分布律:
P{X=k}=pk(1−p)1−k,k=0,1...
二项分布,n重伯努利实验
- 符号: X∼B(n,p)
- 概率分布律:
P{X=k}=Cnkpk(1−p)n−k,k=0,1,2,...,n.
泊松分布
- 符号: X∼P(λ)
- 概率分布律:
P{X=k}=k!e−λλk,k=0,1,2,...
- 代数和性质:n个相互独立的服从泊松分布的随机变量的和仍服从泊松分布,其参数为n个分布的参数之和
- 期望和方差:若X∼P(λ),则E(X)=λ,Var(X)=λ
均匀分布
- 符号:X∼U(a,b)
- 概率密度函数
f(x)=⎩⎨⎧b−a1,x∈(a,b)0,其他
F(x)=⎩⎨⎧0,x<ab−ax−a,a≤x<b1,x≥b
正态分布
- 符号:X∼N(μ,σ)
- 概率密度函数f(x)=2πσ1e−2σ2(x−μ)2(标准正态分布f(x)=2π1e−2x2)
- 代数和性质:n个相互独立的正态变量之和仍为正态变量。且若Xi∼N(μi,σi2),则i=1∑nXi∼N(i=1∑nμi,i=1∑nσi2),甚至可以进一步证明n个相互独立的正态变量的线性组合仍为正态变量
- 期望和方差:若X∼N(μ,σ),则E(X)=μ,Var(X)=σ2
指数分布
- 符号:X∼E(λ)
- 密度函数
f(x)={λe−λx,x>00,x≤0
F(x)=∫−∞xf(t)dt={1−e−λx,x>00,x≤0
- 期望和方差:若X∼E(λ),则E(X)=λ1,Var(X)=λ21
二元均匀分布
f(x,y)=⎩⎨⎧SD1,(x,y)∈D0,其他
二元正态分布
- 符号:(X,Y)∼N(μ1,μ2;σ12,σ22;ρ)
- 密度函数
f(x,y)=2πρ1ρ211−ρ2⋅e−2(1−ρ2)1[σ12(x−μ1)2−2ρσ1σ2(x−μ1)(y−μ2)+σ22(y−μ2)2]
fX(x)=2πσ11e−2σ12(x−μ1)2
fY(y)=2πσ21e−2σ22(x−μ2)2
即X∼N(μ1,σ12),Y∼N(μ2,σ22)
给定X=x
Y∼N(μ2+ρσ1σ2(x−μ1),(1−ρ2σ2)2)
给定Y=y
Y∼N(μ1+ρσ2σ1(y−μ2),(1−ρ2σ1)2)